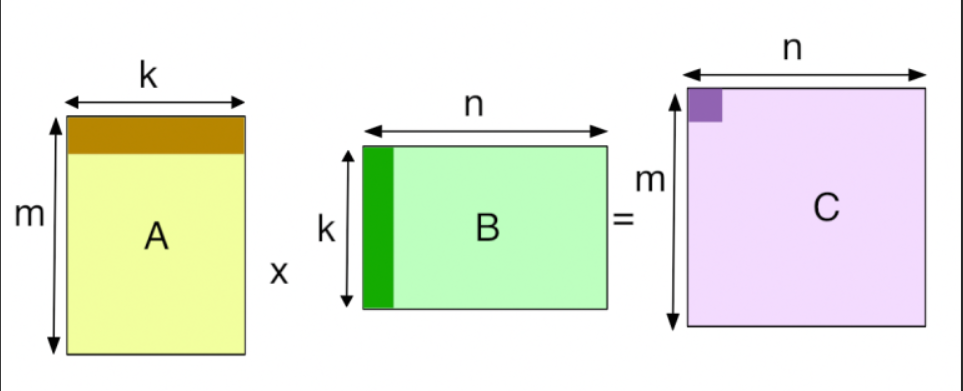
本篇笔记参考如下:
https://zhuanlan.zhihu.com/p/681568740 https://blog.csdn.net/xierhacker/article/details/52744251?ops_request_misc=%257B%2522request%255Fid%2522%253A%25225a3632d0547e40669409db935762a62a%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=5a3632d0547e40669409db935762a62a&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-52744251-null-null.142
内容概览:
写一个CUDA程序
执行一个核函数
用网格和线程块组织线程
GPU性能测试
CUDA编程模型提供了一个计算机架构抽象作为应用程序和其可用硬件之间的桥梁。
CUDA编程模型还利用GPU架构的计算能力提供了以下几个特有功能。
一种通过层次结构在GPU中组织线程的方法
一种通过层次结构在GPU中访问内存的方法
CUDA编程模型使用由C语言扩展生成的注释代码在异构计算系统中执行应用程序。
在一个异构环境中包含多个CPU和GPU,每个GPU和CPU的内存都由一条PCI-Express总线分隔开。因此,需要注意区分以下内容。
主机 :CPU及其内存(主机内存)
设备 :GPU及其内存(设备内存)
从CUDA 6.0开始,NVIDIA提出了名为“统一寻址”(UnifiedMemory)的编程模型的改进,因此现在应学会的是如何为主机和设备分配内存空间以及如何在CPU和GPU之间拷贝共享数据。
主机可以独立地对设备进行操作。内核一旦被启动,管理权立刻返回给主机,释放CPU来执行由设备上运行的并行代码实现的额外的任务。CUDA编程模型主要是异步 的,因此在GPU上进行的运算可以与主机-设备通信重叠。
一个典型的CUDA程序实现流程遵循以下模式。
1.把数据从CPU内存拷贝到GPU内存。
2.调用核函数对存储在GPU内存中的数据进行操作。
3.将数据从GPU内存传送回到CPU内存。
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存 。
用于执行GPU内存分配的是cudaMalloc函数如下:
1 cudaError_t cudaMalloc (void ** devptr, size_t size)
函数负责向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
标准的C函数
CUDA C函数
标准的C函数
CUDA C函数
malloc
cudaMalloc
memset
cudaMemset
memcpy
cudaMemcpy
free
cudaFree
其中cudaMemcpy有这四种
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
内存层次结构
在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。
以下是两个数组相加的例子
主机端sumArraysOnHost.c中的核心代码如下:
1 2 3 4 5 6 7 8 void sumArraysOnHost (float *A, float *B, float *C, const int N) { for (int idx = 0 ; idx < N; idx++) { C[idx] = A[idx] + B[idx]; } }
1.修改为GPU版本,首先用cudaMalloc在GPU上申请内存。
1 2 3 4 float *d_A, *d_B, *d_C;CHECK(cudaMalloc((float **)&d_A, nBytes)); CHECK(cudaMalloc((float **)&d_B, nBytes)); CHECK(cudaMalloc((float **)&d_C, nBytes));
2.用cudaMemcpy函数把数据从主机内存拷贝到GPU的全局内存中
1 2 3 CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
3.当数据被转移到GPU的全局内存后,主机端调用核函数在GPU上进行数组求和。
1 2 3 4 5 6 7 8 sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem); __global__ void sumArraysOnGPU (float *A, float *B, float *C, const int N) { int i = threadIdx.x; if (i < N) C[i] = A[i] + B[i]; }
4.内核在GPU上完成了对所有数组元素的处理后,其结果将以数组d_C的形式存在GPU的全局内存中,然后用cudaMemcpy函数把结果从GPU复制回到主机的数组gpuRef中。
1 CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
cudaMemcpy的调用会导致主机运行阻塞。
5.调用cudaFree释放GPU的内存。
1 2 3 CHECK(cudaFree(d_A)); CHECK(cudaFree(d_B)); CHECK(cudaFree(d_C));
不同的存储空间
CUDA C进行编程的人最常犯的错误就是对不同内存空间的不恰当引用。对于在GPU上被分配的内存来说,设备指针在主机代码中可能并没有被引用。如果执行了错误的内存分配如gpuRef = d_C而不是采用以下办法,应用程序在运行时将会崩溃。
1 cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost)
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程并且每个线程都执行由核函数指定的语句。
1 2 3 4 5 6 7 8 9 gridDim.x:线程网络X维度上线程块的数量 gridDim.y-线程网络Y维度上线程块的数量 blockDim.x-一个线程块X维度上的线程数量 blockDim.y-一个线程块Y维度上的线程数量 blockIdx.x-线程网络X维度上的线程块索引 blockIdx.y-线程网络Y维度上的线程块索引 threadIdx.x-线程块X维度上的线程索引 threadIdx.y-线程块Y维度上的线程索引
书中给出了一个两层的线程层次结构
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内的线程协作可以通过以下方式来实现。
简单来看一下一个例子checkDimension.cu
其中定义了一个包含3个线程的一维线程块,以及一个基于块
和数据大小定义的一定数量线程块的一维线程网格。
1 2 3 int nElem = 6 ;dim3 block (3 ) ; dim3 grid ((nElem+block.x-1 )/block.x) ;
编译并运行
1 2 nvcc -arch=sm_120 ./checkDimension.cu -o check ./check
可以看到以下输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 grid.x 2 grid.y 1 grid.z 1 block.x 3 block.y 1 block.z 1 threadIdx:(0, 0, 0) threadIdx:(1, 0, 0) threadIdx:(2, 0, 0) threadIdx:(0, 0, 0) threadIdx:(1, 0, 0) threadIdx:(2, 0, 0) blockIdx:(0, 0, 0) blockIdx:(0, 0, 0) blockIdx:(0, 0, 0) blockIdx:(1, 0, 0) blockIdx:(1, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) blockDim:(3, 1, 1) blockDim:(3, 1, 1) blockDim:(3, 1, 1) blockDim:(3, 1, 1) blockDim:(3, 1, 1) gridDim:(2, 1, 1) gridDim:(2, 1, 1) gridDim:(2, 1, 1) gridDim:(2, 1, 1) gridDim:(2, 1, 1) gridDim:(2, 1, 1)
Grid (网格) 维度 : grid.x 2 (共 2 个 Block)
Block (线程块) 维度 : block.x 3 (每个 Block 有 3 个 Thread)
总线程数 : 2 × 3 = 6 2 \times 3 = 6 2 × 3 = 6
从主机端和设备端访问网格/块变量
总之,在启动内核之前就定义了主机端的网格和块变量,并从主机端通过由x、y、z三个字段决定的矢量结构来访问它们。当内核启动时,可以使用内核中预初始化的内置变量。
对于一个给定的数据大小,确定网格和块尺寸的一般步骤为:
确定块的大小
在已知数据大小和块大小的基础上计算网格维度
要确定块尺寸,通常需要考虑:
编译并运行defineGridBlock.cu
定义代码如下
1 2 3 4 5 int nElem = 1024 ;dim3 block (1024 ) ; dim3 grid ((nElem + block.x - 1 ) / block.x) ;
1 2 nvcc ./defineGridBlock.cu -o block ./block
结果如下:
1 2 3 4 grid.x 1 block.x 1024 grid.x 2 block.x 512 grid.x 4 block.x 256 grid.x 8 block.x 128
线程层次结构
网格和块的维度存在几个限制因素,对于块大小的一个主要限制因素就是可利用的计算资源,如寄存器,共享内存等。
网格和块从逻辑上代表了一个核函数的线程层次结构,而且每一个线程组织具有不同数量的计算和内存资源。
C语言调用语句如下:
1 FUNCTION_NAME (ARGUMENT LIST);
CUDA内核调用是对C语言函数调用语句的延伸,<<<>>>运算符内是核函数的执行配置。
1 kernel_name <<<grid, block>>>(argument list );
执行配置的第一个值是网格维度,也就是启动块的数目。第二个值是块维度,也就是每个块中线程的数目。通过指定网格和块的维度,可以进行以下配置:
举个例子
32个数据元素用于计算,每8个元素一个块,需要启动4个块:
简单来说,由于数据在全局内存中是线性存储的,因此可以用变量blockIdx.x和threadId.x来进行以下操作。
在网格中标识一个唯一的线程
建立线程和数据元素之间的映射关系
把所有32个元素放到一个块里,那么只会得到一个块:
1 kernel_name <<<1 , 32 >>>(argument list );
如果每个块只含有一个元素,那么会有32个块:
1 kernel_name <<<32 , 1 >>>(argument list );
核函数的调用与主机线程是异步的。核函数调用结束后,控制权立刻返回给主机端。可以调用以下函数来强制主机端程序等待所有的核函数执行结束:
1 cudaError_t cudaDevicesSynchronize (void ) ;
一些CUDA运行时API在主机和设备之间是隐式同步的。例如前面提到的cudaMemcpy函数。
核函数是在设备端执行的代码。在核函数中,需要为一个线程规定要进行的计算以及要进行的数据访问。
以下是用__global__声明定义核函数:
1 __global__ void kernel_name (argument list ) ;
核函数必须有一个void返回类型。
限定符 执行 调用 备注
__global__在设备端执行
可从主机端调用 也可以从计算能力为 3 的设备中调用
必须有一个 void 返回类型
__device__在设备端执行
仅能从设备端调用
__host__在主机端执行
仅能从主机端调用
可以省略
__device__和__host__限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译。
核函数限制:
1 2 3 4 5 只能访问设备内存 必须具有void返回类型 不支持可变数量的参数 不支持静态变量 显示异步行为
在设备端的核函数中使用printf函数进行输出。另外可以通过
<<<1,1>>>强制用一个块和一个线程执行核函数模拟串行执行程序,可用于调试和验证结果。
**处理错误:**定义一个错误处理宏
1 2 3 4 5 6 7 8 9 10 11 #define CHECK(call) { const cudaError_t error = call; if (error != cudaSuccess) { printf ("Error: %S:%d, " , _FILE_· _LINE_); printf ("code:%d, reason: &s(n" , error, cudaGetErrorString(error)); exit (1 ); } }
编译并运行代码sumArraysOnGPU-smallcase.cu
1 2 nvcc sumArraysOnGPU-small-case.cu -o addvector ./addvector
可以得到结果如下:
1 2 3 4 ./addvector Starting... Vector size 32 Execution configure <<<1, 32>>> Arrays match.
修改代码中的块数和线程数
1 2 dim3 block (1 ) ; dim3 grid (nElem) ;
仅修改这个会报错,因为核函数中的索引变化了
1 2 3 4 5 ./addvector Starting... Vector size 32 Execution configure <<<32, 1>>> Arrays do not match! host 19.60 gpu 0.00 at current 1
修改设备端函数的索引,改为
再次编译运行得到正确结果
1 2 3 4 ./addvector Starting... Vector size 32 Execution configure <<<32, 1>>> Arrays match.
通过gettimeofday计时,相关代码如下
1 2 3 4 5 6 7 8 #include <sys/time.h> double cpuSecond () { struct timeval tp ; gettimeofday(&tp,NULL ); return ((double )tp.tv_sec + (double )tp.tv_usec*1.e-6 ); }
当对核函数进行计时时,要注意核函数调用与主机端程序是异步的,需要使用cudaDeviceSynchronize()等待核函数运行结束,以此来记录。
下面以测试向量加法的核函数(sumArraysOnGPUtimer.cu为例
1 2 3 4 5 6 7 8 9 10 11 iStart = seconds(); sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem); CHECK(cudaDeviceSynchronize()); iElaps = seconds() - iStart; iStart = seconds(); sumArraysOnHost(h_A, h_B, hostRef, nElem); iElaps = seconds() - iStart;
其中执行配置为32768个块,512个线程
编译并执行
1 2 nvcc ./sumArraysOnGPU-timer.cu -o sumArraysOnGPU-timer ./sumArrayOnGPU-timer
得到结果如下
1 2 3 4 5 6 7 ./sumArraysOnGPU-timer Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Vector size 16777216 initialData Time elapsed 0.388212 sec sumArraysOnHost Time elapsed 0.016795 sec sumArraysOnGPU <<< 32768, 512 >>> Time elapsed 0.000937 sec Arrays match.
其中CPU计算耗时:0.016795 sec,GPU计算耗时:0.000937 sec。可以看到GPU加速了接近18倍。后续多次测试下,加速比会有不少浮动,其中原因大概是计算量较小,硬件运行会产生波动,只是一个小实验,这里不再深究。
将线程数改为1024和256和128再次运行
16384个线程块,每块1024线程下,加速比可以到17左右:
1 2 3 4 5 6 7 ./sumArraysOnGPU-timer Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Vector size 16777216 initialData Time elapsed 0.373456 sec sumArraysOnHost Time elapsed 0.015702 sec sumArraysOnGPU <<< 16384, 1024 >>> Time elapsed 0.000931 sec Arrays match.
65536个线程块,每块256线程下,加速比可以到2左右:
1 2 3 4 5 6 7 ./sumArraysOnGPU-timer Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Vector size 16777216 initialData Time elapsed 0.381083 sec sumArraysOnHost Time elapsed 0.015421 sec sumArraysOnGPU <<< 65536, 256 >>> Time elapsed 0.007266 sec Arrays match.
131072个线程块,每块128线程下,加速比可以到18左右:
1 2 3 4 5 6 7 ./sumArraysOnGPU-timer Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Vector size 16777216 initialData Time elapsed 0.382991 sec sumArraysOnHost Time elapsed 0.015567 sec sumArraysOnGPU <<< 131072, 128 >>> Time elapsed 0.000840 sec Arrays match.
注意由于硬件设置
1 2 3 --- NVIDIA GeForce RTX 5060 Ti 详细限制 --- 1. 每块最大线程总数: 1024 2. 每个SM的最大线程数: 1536
在较新的 CUDA 版本( CUDA 11.0 )中,nvprof 已经被正式弃用,并被全新的性能分析工具工具套件 Nsight Systems 取代了。
1 2 3 4 5 # 耗时统计摘要 nsys profile --stats=true ./sumArraysOnGPU-timer # nsys profile --stats=true --force-overwrite=true ./sumArraysOnGPU-timer
输入命令
1 nsys profile --stats=true ./sumArraysOnGPU-timer
得到如下结果
占比 (%) 总耗时 (ns) 调用次数 平均耗时 (ns) 中位数 (ns) 最小值 (ns) 最大值 (ns) 标准差 (ns) API 名称
92.1 31,549,099
4
7,887,274.8
7,655,609.0
6,962,628
9,275,253
1,037,472.0
cudaMemcpy
3.0
1,035,717
3
345,239.0
311,957.0
264,362
459,398
101,688.4
cudaMalloc
2.3
771,950
3
257,316.7
188,258.0
171,606
412,086
134,292.5
cudaFree
1.5
510,039
1
510,039.0
510,039.0
510,039
510,039
0.0
cudaDeviceSynchronize
0.8
265,707
1
265,707.0
265,707.0
265,707
265,707
0.0
cuLibraryLoadData
0.4 139,221
1
139,221.0
139,221.0
139,221
139,221
0.0
cudaLaunchKernel
0.0
576
1
576.0
576.0
576
576
0.0
cudaGetDeviceProperties
0.0
529
1
529.0
529.0
529
529
0.0
cuModuleGetLoadingMode
0.0
403
1
403.0
403.0
403
403
0.0
cuLibraryGetKernel
0.0
310
1
310.0
310.0
310
310
0.0
cuKernelGetName
在2.2节中可以发现,不同的网格和块大小组织线程,对内核的性能会产生很大的影响。同样的程序下65536个线程块,每块256线程,加速比只有2左右,而16384个线程块,每块1024线程可以达到17~18倍。因此我们可以通过调整块的大小,并基于块大小和向量数据大小计算出网格大小来实现最佳性能。
对于一个矩阵加法核函数来说,一个线程通常被分配一个数据元素处理,在进行计算过程中,需要管理三种索引。图中矩阵为8列6行。
1 2 3 ·线程和块索引 ·矩阵中给定点的坐标 ·全局线性内存中的偏移量
第一步:把线程和块索引映射到矩阵坐标上
1 2 int ix = threadIdx.x + blockIdx.x * blockDim.x;int iy = threadIdx.y + blockIdx.y * blockDim.y;
第二步:把矩阵坐标映射到全局内存中的索引/存
储单元
1 unsigned int idx = iy * nx + ix;
编译并运行checkThreadIndex.cu,注意,这是一个二维线程块构成二维网格
1 2 nvcc -arch=sm_120 ./checkThreadIndex.cu -o checkIndex ./checkIndex
得到结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 Matrix: (8.6) 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 thread_id (0,0) block_id (1,2) coordinate (4,4) global index 36 ival 36 thread_id (1,0) block_id (1,2) coordinate (5,4) global index 37 ival 37 thread_id (2,0) block_id (1,2) coordinate (6,4) global index 38 ival 38 thread_id (3,0) block_id (1,2) coordinate (7,4) global index 39 ival 39 thread_id (0,1) block_id (1,2) coordinate (4,5) global index 44 ival 44 thread_id (1,1) block_id (1,2) coordinate (5,5) global index 45 ival 45 thread_id (2,1) block_id (1,2) coordinate (6,5) global index 46 ival 46 thread_id (3,1) block_id (1,2) coordinate (7,5) global index 47 ival 47 thread_id (0,0) block_id (0,2) coordinate (0,4) global index 32 ival 32 thread_id (1,0) block_id (0,2) coordinate (1,4) global index 33 ival 33 thread_id (2,0) block_id (0,2) coordinate (2,4) global index 34 ival 34 thread_id (3,0) block_id (0,2) coordinate (3,4) global index 35 ival 35 thread_id (0,1) block_id (0,2) coordinate (0,5) global index 40 ival 40 thread_id (1,1) block_id (0,2) coordinate (1,5) global index 41 ival 41 thread_id (2,1) block_id (0,2) coordinate (2,5) global index 42 ival 42 thread_id (3,1) block_id (0,2) coordinate (3,5) global index 43 ival 43 thread_id (0,0) block_id (0,0) coordinate (0,0) global index 0 ival 0 thread_id (1,0) block_id (0,0) coordinate (1,0) global index 1 ival 1 thread_id (2,0) block_id (0,0) coordinate (2,0) global index 2 ival 2 thread_id (3,0) block_id (0,0) coordinate (3,0) global index 3 ival 3 thread_id (0,1) block_id (0,0) coordinate (0,1) global index 8 ival 8 thread_id (1,1) block_id (0,0) coordinate (1,1) global index 9 ival 9 thread_id (2,1) block_id (0,0) coordinate (2,1) global index 10 ival 10 thread_id (3,1) block_id (0,0) coordinate (3,1) global index 11 ival 11 thread_id (0,0) block_id (1,0) coordinate (4,0) global index 4 ival 4 thread_id (1,0) block_id (1,0) coordinate (5,0) global index 5 ival 5 thread_id (2,0) block_id (1,0) coordinate (6,0) global index 6 ival 6 thread_id (3,0) block_id (1,0) coordinate (7,0) global index 7 ival 7 thread_id (0,1) block_id (1,0) coordinate (4,1) global index 12 ival 12 thread_id (1,1) block_id (1,0) coordinate (5,1) global index 13 ival 13 thread_id (2,1) block_id (1,0) coordinate (6,1) global index 14 ival 14 thread_id (3,1) block_id (1,0) coordinate (7,1) global index 15 ival 15 thread_id (0,0) block_id (1,1) coordinate (4,2) global index 20 ival 20 thread_id (1,0) block_id (1,1) coordinate (5,2) global index 21 ival 21 thread_id (2,0) block_id (1,1) coordinate (6,2) global index 22 ival 22 thread_id (3,0) block_id (1,1) coordinate (7,2) global index 23 ival 23 thread_id (0,1) block_id (1,1) coordinate (4,3) global index 28 ival 28 thread_id (1,1) block_id (1,1) coordinate (5,3) global index 29 ival 29 thread_id (2,1) block_id (1,1) coordinate (6,3) global index 30 ival 30 thread_id (3,1) block_id (1,1) coordinate (7,3) global index 31 ival 31 thread_id (0,0) block_id (0,1) coordinate (0,2) global index 16 ival 16 thread_id (1,0) block_id (0,1) coordinate (1,2) global index 17 ival 17 thread_id (2,0) block_id (0,1) coordinate (2,2) global index 18 ival 18 thread_id (3,0) block_id (0,1) coordinate (3,2) global index 19 ival 19 thread_id (0,1) block_id (0,1) coordinate (0,3) global index 24 ival 24 thread_id (1,1) block_id (0,1) coordinate (1,3) global index 25 ival 25 thread_id (2,1) block_id (0,1) coordinate (2,3) global index 26 ival 26 thread_id (3,1) block_id (0,1) coordinate (3,3) global index 27 ival 27
本节中,我们使用一个二维网格和二维块来编写一个矩阵加法核函数。
代码为sumMatrixOnGPU-2D-grid-2D-block.cu
1.校验核函数(验证矩阵加法核函数是否正确)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void sumMatrixOnHost (float *A, float *B, float *C, const int nx, const int ny) { float *ia = A; float *ib = B; float *ic = C; for (int iy = 0 ; iy < ny; iy++) { for (int ix = 0 ; ix < nx; ix++) { ic[ix] = ia[ix] + ib[ix]; } ia += nx; ib += nx; ic += nx; } return ; }
2.采用二维线程块进行矩阵求和
1 2 3 4 5 6 7 8 9 10 __global__ void sumMatrixOnGPU2D (float *MatA, float *MatB, float *MatC, int nx, int ny) { unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y; unsigned int idx = iy * nx + ix; if (ix < nx && iy < ny) MatC[idx] = MatA[idx] + MatB[idx]; }
注意分块方式,保证每个线程从它的线程索引映射到全局线
性内存索引中
1 2 3 4 5 6 7 int nx = 1 << 14 ;int ny = 1 << 14 ;int dimx = 32 ;int dimy = 32 ;dim3 block (dimx, dimy) ; dim3 grid ((nx + block.x - 1 ) / block.x, (ny + block.y - 1 ) / block.y) ;
编译并运行sumMatrixOnGPU-2D-grid-2D-block.cu
1 2 nvcc -arch=sm_120 sumMatrixOnGPU-2D-grid-2D-block.cu -o matrix2D ./matrix2D
块的尺寸大小为32×32,得到结果如下
1 2 3 4 5 6 7 ./matrix2D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 Matrix initialization elapsed 6.310907 sec sumMatrixOnHost elapsed 0.296464 sec sumMatrixOnGPU2D <<<(512,512), (32,32)>>> elapsed 0.010220 sec Arrays match.
调整块的尺寸大小为32×16,得到结果
1 2 3 4 5 6 7 ./matrix2D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 Matrix initialization elapsed 6.396843 sec sumMatrixOnHost elapsed 0.269564 sec sumMatrixOnGPU2D <<<(512,1024), (32,16)>>> elapsed 0.009309 sec Arrays match.
调整块的尺寸大小为16×16,得到结果
1 2 3 4 5 6 7 8 (cuda_env) root@255ce688f65c:~/cuda_learn/cuda_program/CodeSamples/chapter02# ./matrix2D ./matrix2D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 Matrix initialization elapsed 6.083118 sec sumMatrixOnHost elapsed 0.280569 sec sumMatrixOnGPU2D <<<(1024,1024), (16,16)>>> elapsed 0.010115 sec Arrays match.
在书中,从所得到的运行结果可以看出,不同执行配置对核函数影响较大,然而如今在新的硬件和软件的架构配合和优化下,可以发现,差别不是很大,由于波动的原因导致无法准确判断执行配置对核函数的影响。不可否认的是在多次测试下,仍可以初步得到(32,16)的内核配置可以得到更好的结果。
书中结果为:
本文结果为如下
内核配置
内核运行时间
线程块数
(32,32)
0.010220 s
512×512
(32,16)
0.009309 s
512×1024
(16,16)
0.010115 s
1024×1024
这里简单分析一下原因,在后续章节会详细分析
sm_20 (Fermi)768 KB )。如果线程块配置不合理导致访存模式不够整齐,数据会频繁落到慢速的显存(VRAM)上,产生巨大的延迟。另一个原因是指令发射器比较简单,一旦线程块因为访存等待(Memory Stall)停下来,如果没有足够的备用线程块来切换,GPU 就会“空转”。
sm_120 (RTX 5060 Ti)32 MB 的 L2 缓存
这个量级的缓存足以把大部分向量数据直接“吞”进缓存里。
即使内核配置(线程分配方式)不是最优的,巨大的 L2 缓存也能极大地缓解访存压力,掩盖了线程调度上的小瑕疵。
现代 GPU 拥有更强大的指令并行性 (ILP) 和更聪明的调度器 。它能更有效地在不同线程之间切换以隐藏延迟。对于向量加法这种简单的计算,RTX 5060 Ti 的硬件性能已经远远超出了任务需求,表现为一种“性能饱和”状态,所以无论怎么切分线程块,结果都差不多快。
在本节中,我们使用一维网格和一维块。
其中全局索引为
此时,只有threadIdx.x是有用的,可以使用内核中的一个循环来处理每个线程中的ny个元素。
核函数代码如下
1 2 3 4 5 6 7 8 9 10 11 12 __global__ void sumMatrixOnGPU1D (float *MatA, float *MatB, float *MatC, int nx, int ny) { unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; if (ix < nx ) for (int iy = 0 ; iy < ny; iy++) { int idx = iy * nx + ix; MatC[idx] = MatA[idx] + MatB[idx]; } }
内核配置如下
1 2 3 4 5 6 int nx = 1 << 14 ;int ny = 1 << 14 ;int dimx = 32 ;dim3 block (dimx, 1 ) ; dim3 grid ((nx + block.x - 1 ) / block.x, 1 ) ;
编译并执行sumMatrix-OnGPU-1D-grid-1D-block.cu
1 2 nvcc -arch=sm_120 sumMatrixOnGPU-1D-grid-1D-block.cu -o matrix1D ./matrix1D
得到结果如下
1 2 3 4 5 6 7 ./matrix1D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 initialize matrix elapsed 6.184577 sec sumMatrixOnHost elapsed 0.269148 sec sumMatrixOnGPU1D <<<(512,1), (32,1)>>> elapsed 0.011575 sec Arrays match.
将以上结果与个二维网格和块(32×32)的配置结果相比,性能基本没有变化
将块大小增大至128,即每块的线程数增大至128,得到结果如下
1 2 3 4 5 6 7 ./matrix1D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 initialize matrix elapsed 6.284464 sec sumMatrixOnHost elapsed 0.263191 sec sumMatrixOnGPU1D <<<(128,1), (128,1)>>> elapsed 0.010615 sec Arrays match.
可以看到相比32块 大小的结果快了一点
在本节中,使用一个包含一维块的二维网格
全局索引为
1 2 3 unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = blockIdx.y;unsigned int idx = iy * nx + ix;
核函数如下
1 2 3 4 5 6 7 8 9 10 __global__ void sumMatrixOnGPUMix (float *MatA, float *MatB, float *MatC, int nx, int ny) { unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; unsigned int iy = blockIdx.y; unsigned int idx = iy * nx + ix; if (ix < nx && iy < ny) MatC[idx] = MatA[idx] + MatB[idx]; }
内核配置如下
1 2 3 4 5 int nx = 1 << 14 ;int ny = 1 << 14 ;int dimx = 32 ;dim3 block (dimx, 1 ) ; dim3 grid ((nx + block.x - 1 ) / block.x, ny) ;
编译并运行sumMatrixOnGPU-2D-grid-1D-block.cu
1 2 nvcc -arch=sm_120 sumMatrixOnGPU-2D-grid-1D-block.cu -o mat2D1D ./mat2D1D
得到结果如下
1 2 3 4 5 6 7 ./mat2D1D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 Matrix initialization elapsed 6.147125 sec sumMatrixOnHost elapsed 0.268224 sec sumMatrixOnGPU2D <<<(512,16384), (32,1)>>> elapsed 0.010723 sec Arrays match.
将线程块大小增加到256,即每块的线程数为256
得到结果如下
1 2 3 4 5 6 7 ./mat2D1D Starting... Using Device 0: NVIDIA GeForce RTX 5060 Ti Matrix size: nx 16384 ny 16384 Matrix initialization elapsed 6.050290 sec sumMatrixOnHost elapsed 0.269842 sec sumMatrixOnGPU2D <<<(64,16384), (256,1)>>> elapsed 0.015621 sec Arrays match.
书中在这里指出,这个内核配置表现出了最佳的性能 ,然而在我现在实际测试中,并不算是最好的配置,所以不作评价。
总体来说,可以得到这样的结论:
改变执行配置对内核性能有影响
传统的核函数实现一般不能获得最佳性能
对于一个给定的核函数,尝试使用不同的网格和线程块大小可以获得更好的性能
NVIDIA提供了几个查询和管理GPU设备的方法。
采用以下函数查询关于GPU设备的所有信息
1 cudaGetDeviceProperties(&deviceProp, dev)
编译并执行checkDeviceInfor.cu
1 2 nvcc checkDeviceInfor.cu -o checkDeviceInfor ./checkDeviceInfor
可以得到以下结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ./checkDeviceInfor Starting... Detected 1 CUDA Capable device(s) Device 0: "NVIDIA GeForce RTX 5060 Ti" CUDA Driver Version / Runtime Version 13.0 / 13.0 CUDA Capability Major/Minor version number: 12.0 Total amount of global memory: 15.93 GBytes (17102864384 bytes) Memory Bus Width: 128-bit L2 Cache Size: 33554432 bytes Max Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384) Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048 Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block: 1024 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535 Maximum memory pitch: 2147483647 bytes
详细参数解读:
1. 核心计算能力 (Compute Capability)
CUDA Capability Major/Minor version number: 12.0
解读: 代表了显卡的架构版本。12.0 是非常前沿的架构。它决定了显卡支持哪些指令集和硬件特性(比如是否支持特定的原子操作、Tensor Core 的代际等)。
Warp size: 32
解读: CUDA 调度的最小单位。32 个线程组成一个 Warp,它们在硬件上是同步执行的。这个值在 NVIDIA 历史上基本没变过。
2. 显存与带宽 (Memory)
Total amount of global memory: 15.93 GBytes
Memory Bus Width: 128-bit
解读: 显存位宽。128-bit 属于中端显卡的标配,位宽决定了显存频率一定时,数据传输的速度上限。
L2 Cache Size: 33554432 bytes (32 MB)
解读: 二级缓存。较大的 L2 缓存可以减少对显存的直接访问压力,显著提升着色器或计算核函数的性能。
3. 线程层级限制 (Execution Configuration)
这部分决定了写 CUDA 代码时 <<<grid, block>>> 参数的上限:
Maximum number of threads per block: 1024
解读: 单个线程块(Block)内最多能容纳 1024 个线程。
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
**解读:**可以将 Block 设置为 1D, 2D 或 3D 布局,但三者乘积不能超过上面的 1024。
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
解读: Grid 的 X 维度几乎是无限的(21亿),这意味着可以一次性启动海量的任务。
4. 寄存器与共享内存 (Memory Resources)
Total number of registers available per block: 65536
解读: 寄存器是 GPU 上最快的存储。每个 Block 有 64K 个 32-bit 寄存器。如果你的每个线程占用的寄存器太多,能并行执行的 Block 数量就会减少。
Total amount of shared memory per block: 49152 bytes (48 KB)
解读: 共享内存在 Block 内部通用,速度极快。48 KB 是默认配置,通常可以通过编程调整(如果硬件支持,有时可调至更高,如 96KB 或更多)。
5. 纹理与常量内存 (Texture & Constant Memory)
Total amount of constant memory: 65536 bytes (64 KB)
解读: 常量内存,用于存放程序运行期间不改变的数据,带有缓存机制,适合所有线程读取同一数据的情况。
Max Texture Dimension Size: 这部分描述了 GPU 处理图像纹理数据时的最大尺寸限制。对于通用计算(GPGPU)用户来说,通常关注度较低。
nvidia-smi是一个命令行工具,用于管理和监控GPU设备,并允许查询和修改设备状态。
输入命令nvidia-smi -L可以查看系统中安装了多少个GPU以及每个GPU的设备ID
1 2 (base)root@255ce688f65c:~/cuda_learn/cuda_program/CodeSamples/chapter02# nvidia-smi -L GPU 0: NVIDIA GeForce RTX 5060 Ti (UUID: GPU-4d10ca70-42d6-2446-4af2-761721e7105d)
输入命令nvidia-smi可得到基本信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 (base) root@255ce688f65c:~/cuda_learn/cuda_program/CodeSamples/chapter02# nvidia-smi Sun Jan 11 07:57:17 2026 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.95.02 Driver Version: 581.42 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 5060 Ti On | 00000000:01:00.0 On | N/A | | 0% 40C P3 18W / 180W | 3758MiB / 16311MiB | 9% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 22 G /Xwayland N/A | +-----------------------------------------------------------------------------------------+
其余命令不再赘述。
支持多GPU的系统是很常见的。对于一个有N个GPU的系统,nvidia-smi从0到N―1标记设备ID。使用环境变CUDA_VISIBLE_DEVICES,就可以在运行时指定所选的GPU且无须更改应用程序。
设置运行时环境变量CUDA_VISIBLE_DEVICES=2。nvidia驱动程序会屏蔽其他GPU,这时设备2作为设备0出现在应用程序中。
与C语言的并行编程相比,CUDA程序中的线程层次结构是独有的,通过一个抽象的两级线程层次结构,CUDA能够控制一个大规模并行环境。