GEMM优化实战
GEMM 算子详解
本篇参考:
https://zhuanlan.zhihu.com/p/1910636263666610461
https://zhuanlan.zhihu.com/p/703256080
https://zhuanlan.zhihu.com/p/441146275
1 概念
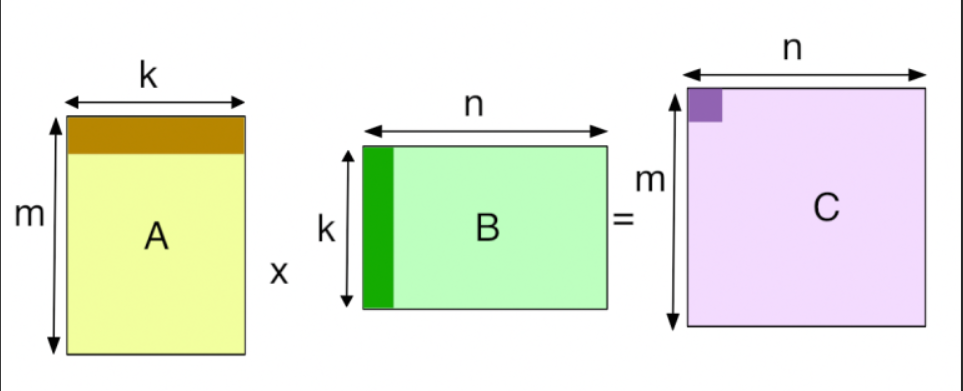
从数学上讲,GEMM 描述的是一个非常基础的线性代数运算:
其中:
- 是 的矩阵。
- 是 的矩阵。
- 是 的结果矩阵。
- 和 是常数标量(通常 )。
深度学习中 90% 以上的计算量都来自矩阵乘法:
- 全连接层(Linear/FC):本质就是 GEMM。
- 卷积层(Conv2d):通过一种叫 im2col 的技术,卷积运算会被转化为 GEMM 运行,以利用 GPU 的极致算力。
- Transformer(大模型):其核心的 Attention 机制本质上是多组连续的 GEMM 运算。

2 cuBLAS实现
本文采用cuBLAS 提供的矩阵乘法算子 cublasSgemm作为基准进行手动调优。
接口代码如下:
1 | checkCudaErrors(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, M, K, |
其中:
1 | float alpha = 1.0f; |
3 朴素实现
而在 CUDA 编程中,我们将最外层的两层循环(行和列)“展开”到了 GPU 的网格(Grid)和线程块(Block)中。
- 每个线程的任务:计算输出矩阵 中的一个特定元素 。
- 并行度:如果有 个元素,GPU 就会启动至少 个线程同时进行计算。
核函数代码如下:
1 | __global__ void naive_gemm(float *A, float *B, float *C, int M, int N, int K) |
其中M = 2048, N = 2048, K = 2048
| Time (ms) | 相对效率 | |
|---|---|---|
| cublasSgemm | 1.21672 | 100% |
| naiveGEMM | 13.10449. | 9.3% |
4 优化一:矩阵分块计算
1.优化一:为了减少 global memory 的访问量,我们将需要重复读取的数据转移到了shared memory中,但由于 shared memory 的资源有限,且只在block内共享,我们让每个block负责矩阵C中一块区域的计算。

图中可以看出,在计算输出矩阵的子块 时,输入矩阵 的行切片与 的列切片表现出极高的时间局部性。虽然理论上将这些切片完整映射至 Shared Memory 可最大化减少对Global Memory的访问,但受限于 GPU 硬件架构中SM极其有限的静态共享内存容量,当内层维度 较大时,所需的中间数据量将超过硬件的存储阈值。
解决方法:K-Loop
为解决上述问题,可以在 K 所在的维度上进行进一步拆分,通过多次循环完成 tileC 的计算,如下图所示:

对于切片和切片来说可以采取外积的形式进行计算
**向量内积:**读取A中一行向量, B中一列向量,计算向量内积,结果为C中一个元素
**向量外积:**读取A中一列向量, B中一行向量,计算向量外积,结果为与C等大的矩阵,多次循环累加得到最终结果 。
向量外积有一个重要的特点是矩阵 中的列向量和矩阵 中的行向量只需要参与计算一次。这意味着我们可以一次性读取完两个向量,二者完成计算后即可丢弃,直接读取下一次数据。其中,可用的优化方法有:
- 使用寄存器存储A中的列向量和B中的行向量
- 使用向量化访存读取数据
- 使用 double-buffer(双缓存)策略,预取数据
计算流程
- 第一阶段:高效加载 (Global Shared)
为了让搬运效率达到最高,代码根据 ()和 ()的形状动态调整了线程的逻辑排列。
-
读取 时:线程排列为 ,步长式读取。
-
读取 时:线程排列为 ,步长式读取。
这样保证了在行优先存储的矩阵中,相邻线程始终读取相邻地址。
- 第二阶段:计算核心 (Shared Registers)
采用向量外积逻辑:
-
在 维的小循环内,每个线程从 取 8 个数,从 取 8 个数。
-
在寄存器内完成 的外积运算并累加到
Ct。 -
优势:极大地提高了指令流强度,通过
__syncthreads()保证了数据的生产-消费同步。 -
第三阶段:写回 (Registers Global)
计算完成后,将每个线程寄存器数组 Ct 中的 64 个值映射回矩阵 的全局坐标。这里需要注意跨步计算,因为每个线程负责的 64 个点在全局矩阵中是呈“网格状”分布的,而非紧挨着的。
5 优化二:线程分块计算
在优化一中,每个 thread 负责计算 tileC 中 8×8 个元素,对应 tileA 中 8×8 子数组与 tileB 中 8×8 子数组的矩阵相乘。在此基础上,线程分块进行了以下优化:
-
使用 register 存储 shared memory 中的数据,提高带宽;
-
p-Loop,先循环 k 维度,分别存储 A 中列向量到 regA,存储 B 中行向量到 regB
主要修改代码如下
1 | float regA[Tm] = {0.0f}; |
6 优化三:调整 warp 尺寸
之前的 threadTileGEMM(1D 映射):
1 | int C_THREAD_Y = tid / C_BLOCK_X; // C_BLOCK_X 通常为 16 |
现在的 warpGEMM(2D 映射): 代码通过 warpId 和 laneId 的计算,明确规定了一个 Warp 内部的 32 个线程被排列成 的 2D 网格(C_WARP_Y = 4, C_WARP_X = 8)。
- 读取
As时
1 | regA[i] = As[r][p]; // r 依赖于 C_THREAD_Y, p 是固定的 |
在同一个 Warp 内,有 8 个线程拥有相同的 Y 坐标。当它们去读取 As[r][p] 时,实际上是 8 个线程在请求 Shared Memory 中完全相同的物理地址。它不会发生冲突,而是直接触发一次读取,然后将数据广播给这 8 个线程。这极大节省了读取周期。
- 读取
Bs时
1 | regB[j] = Bs[p][c]; // c 依赖于 C_THREAD_X, p 是固定的 |
在同一个 Warp 内,有 4 个线程拥有相同的 X 坐标。这 4 个线程会请求相同的 Bs 地址,再次触发硬件广播。
7 优化四:向量化读取 shared memory(float4GEMM)
1. 向量化访存
在之前的代码中,从 Shared Memory 读取数据到寄存器是一次读一个 float(32 bit)。
在当前代码的 p-Loop 中有
1 | #define FLOAT4(value) (reinterpret_cast<float4*>(&(value))[0]) |
- 原理解析:
FLOAT4(底层实际上是float4内置向量类型)允许一个线程通过**一条汇编指令(LDG.128 / LDS.128)**一次性读取 128-bit(即 4 个连续的float)。 - 收益:这不仅极大地减少了访存指令的发射数量(指令数减少为原来的 1/4),降低了指令调度开销,还能最大化利用 GPU 硬件总线的访存位宽。
2. tileA 的 Shared Memory 转置
- 之前的代码:
__shared__ float As[Bm][Bk]; - 现在的代码:
__shared__ float As[Bk][Bm];
在计算外积时(p-Loop),我们需要从 As 中取出一列向量,从 Bs 中取出一行向量。
- 取
Bs的一行很简单,因为 C/C++ 是行优先存储的,一行的数据在内存中是连续的,可以直接用float4完美读取。 - 但是,取
As的一列时,数据在内存中是跳跃的(步长为Bk)。float4强行要求读取的 4 个元素必须在物理内存上严格连续。 - 破局之法:代码在 Global Memory 存入 Shared Memory 的那一刻,直接将
tileA转置了!把原来的列变成了行,这样在p-Loop中读取As时,就变成了连续访问,从而完美解锁float4。
3. XOR(异或)解决 Bank Conflicts
由于我们把 As 转置了,在写入和读取 As 时,不可避免地会打破原来的多播(Broadcast)完美平衡,导致同一个 Warp 内的不同线程同时访问同一个 Bank 的不同层(Bank Conflict),造成严重的排队延迟。
数据布局错位(Swizzling):
1 | // 写入时错位 |
- 科学原理解析:这里的
^是按位异或操作。通过将内层维度坐标i与外层维度坐标j的倍数进行异或,原本应该落在同一个 Bank 的数据,被“伪随机”且均匀地打散到了其他的 Bank 中。 - 对称性:因为异或操作具有对称性(),只要在写(存入 Shared Memory)和读(加载到寄存器)的时候使用完全相同的异或映射公式,就能完美取回正确位置的数据,同时在物理层面上实现了 0 Bank Conflict。
4. 坐标映射的复杂化(写回矩阵 )
由于引入了 float4,每个线程实际上处理的数据块不再是之前简单的线性递增。因此在最后将寄存器 Ct 写回 Global Memory 的矩阵 时,坐标计算变得相当复杂:
1 | int r = r0 + 4 * C_THREAD_Y + i / 4 * 4 * C_BLOCK_Y + i % 4; |
这是一种典型的“以算代存”策略:由于写回 Global Memory 在整个 Kernel 中只发生一次,即便这里的索引计算稍微复杂了一点点(多了一些加减乘除),相比于在百万次 K-Loop 循环中省下的 Shared Memory 访存时间,这种代价微乎其微。
8 优化五:解决 Bank Conflicts
引入 ^ (4 \* p)(错位魔法):
- 这里的
p是行号(K维度)。 4 * p相当于根据当前所在的行,生成一个基于行的动态偏移量。- 通过按位异或
r ^ (4 * p),我们强制把原本在同一个 Bank 里的数据,打散(Shift)到了其他的 Bank 中。由于异或是双射操作(没有哈希碰撞),且我们在存入和读取时都应用了同一个动态偏移量(4 * j)和(4 * p),数据在物理上被均匀错开,但在逻辑上又能被完美、正确地取回。
在朴素的分块中,一个线程负责 的离散点。但使用了 float4 后,由于必须一次性连续取 4 个数,线程计算的 变成了由 个“ 小实心块”组成的矩阵。
我们以行坐标 r 为例,分析变量 i(从 0 循环到 7):
- 基础偏移:
r0是当前 Block 负责的tileC的起始位置。 - 线程局部偏移:
4 * C_THREAD_Y。因为每个线程一次处理 4 个连续元素,所以线程与线程之间的基础间隔被放大了 4 倍。 - 分块跳跃(
i / 4):- 当 时,
i / 4 = 0。此时在处理第一个连续的 4 个数。 - 当 时,
i / 4 = 1。此时需要跳到下一个逻辑分块。跳多远呢?跳过整个C_BLOCK_Y的跨度,且因为每次按 4 个元素处理,所以跳跃步长是4 * C_BLOCK_Y(即 )。
- 当 时,
- 块内偏移(
i % 4): 这就是当前在连续 4 个元素中的具体哪一个(偏移量 0, 1, 2, 3)。
通过这种复杂的模运算和整除运算,代码完美地把逻辑上的连续循环 i,映射到了经过 float4 撕裂后的全局显存物理坐标上,保证了最后写入时依然能够最大程度利用合并访存。
9 优化六:写法优化
(1) 运算优化:使用位运算代替耗时的除法和求余运算
(2) 循环优化:循环展开,减少冗余写法
(3) 常量优化:使用模板参数传递常量
- 位运算
之前的代码中,存在大量的整数除法 /、取余 % 和乘法 * 操作。整数加减法和位运算通常只需要 1 个时钟周期,而整数除法和取余是非常昂贵的操作(可能需要几十个周期,或者由编译器翻译成一长串复杂的指令)。
只要除数是 2 的幂次方,就可以完美替换:
-
取余替换为按位与(
&):- 原代码:
tid % A_BLOCK_X(假设为 8) - 现代码:
tid & (A_BLOCK_X - 1)即tid & 7。 - 效果:耗时的
%被替换成了极速的&。
- 原代码:
-
乘除法替换为移位(
>>和<<):-
原代码:
i / 4和i * 4 -
现代码:
i >> 2和i << 2。 -
效果:直接操作寄存器位,省去了乘法器和除法器的开销。
-
- Z-Order
Z-Order(Z 曲线)或 微分块(Micro-tiling) 的排列。
把前 4 个线程(laneId = 0, 1, 2, 3)代入公式算一下:
laneId = 0laneX = 0, laneY = 0laneId = 1laneX = 0, laneY = 1laneId = 2laneX = 1, laneY = 0laneId = 3laneX = 1, laneY = 1
连续的 4 个线程不再是排成一条横线,而是紧紧抱团形成了一个 的小方块。
由于我们使用了 float4,每个线程负责一块数据。当相邻的线程在物理空间上以 抱团时,它们在读写 Global Memory 时,访存地址在二维空间上更加紧凑。这能极大提升 L1 / L2 Cache 的缓存命中率(Cache Line Locality),使得 GPU 的内存子系统工作得更舒服。
- 循环不变量外提
- 优化前(在 for 循环内部计算行列坐标):
- 优化后(提取到循环外部):
- 模板参数化
所有的常量(如 A_BLOCK_X, Tm, Tn)全都被塞进了 template<...> 里面。所有的计算(如 Tm >> 2)都会在编译时直接折叠成常量数字(如 2)。在最终生成的机器码中,没有任何变量的计算开销,全部变成了写死的立即数(Immediate Values),这极大降低了寄存器的动态占用。
结语
GEMM算子涉及了大量的CUDA编程优化方法,除了上文提到的外,还有双缓冲等优化方法。