

论文分享:Kerncap
论文分享-Kerncap
1 整体介绍
论文:https://arxiv.org/abs/2605.03208
Kerncap:给定“大型应用 + 目标 Kernel 名称”,自动把这个 Kernel 连同当时的参数、显存状态、二进制、源码和编译环境一起打包出来。
例如:开发者修改 Kernel 后,不再需要反复编译和运行整个 llama.cpp、LAMMPS 或 vLLM,而是直接在一个小型独立项目中执行:
123456789修改 Kernel ↓只编译该 Kernel ↓恢复原始 GPU 输入 ↓独立执行 Kernel ↓与原始输出比较
2 前置知识
一个 GPU Kernel 可能只有几十到几百行代码,但真正让它独立运行,需要同时恢复三类信息。
2.1 Kernel Definition:Kernel 定义
包括:
Kernel 的 HSACO 二进制;
原始源码;
头文件依赖;
模板实例化对应的翻译单元;
编译宏、包含路径和优化选项;
GPU 架构参数,例如 gfx942。
2.2 Runtime State:运行时状态
包括:
Gr ...

论文分享:Record Remix Replay
论文分享-Record-Remix-Replay
如何让大模型修改复杂 GPU Kernel 源码,同时又能够快速、可靠地评估每个候选版本,并进一步为每个源码版本找到合适的编译器 Pass 和 Kernel 启动参数?
核心思路:
12345678外层:LLM + MAP-Elites 搜索源码实现、算法结构和代码重写内层:贝叶斯优化 搜索编译器 Pass、编译参数和 Launch Configuration底层:GPU Kernel Record-Replay 独立、快速、可重复地运行候选 Kernel
真实 GPU 应用的性能由多个层次共同决定:
123456789算法选择 ↓Kernel 源码实现 ↓编译器优化和 Pass 顺序 ↓线程块大小、Grid 大小、Launch Bounds ↓实际硬件执行行为
例如,一个 Kernel 是否适合使用 256 个线程,并不仅由 Kernel 的输入大小决定,还取决于:
源码中是否展开了循环;
使用了多少寄存器;
是否使用共享内存;
编译器是否完成常量传播;
内联后代码规模是否增大;
当前代码 ...

建站手册:腾讯云服务器部署Hexo
建站手册:腾讯云服务器部署Hexo
写在前面:欢迎来踩我的个人博客~:earnshawn.cn
1 背景
本人服务器到期,且目前网络上大多数的攻略均基于github进行搭建个人网站,本人当时就想着用自己服务器,查阅资料时,很少有人提及如何将hexo网站:https://hexo.io/zh-cn/ 部署到个人网站上,我也因此踩了很多坑。因此这次服务器到期,想着从0到1开始搭建,内容包括:服务器相关内容下载,部署方式,备案等,希望能够帮助到有需要的人。
服务器版本为:ubuntu22.04
123456789101112PRETTY_NAME="Ubuntu 22.04.5 LTS"NAME="Ubuntu"VERSION_ID="22.04"VERSION="22.04.5 LTS (Jammy Jellyfish)"VERSION_CODENAME=jammyID=ubuntuID_LIKE=debianHOME_URL="https://www.ubuntu.com/"SUPP ...
【CUDA】(七)调整指令级原语
(七)调整指令级原语
本篇笔记参考如下:
https://blog.csdn.net/gao_zhennan/article/details/120717424?ops_request_misc=elastic_search_misc&request_id=8a12ee6315cc5ba5c95b4dc10ccb3baf&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-120717424-null-null.142
本章重点介绍计算密集型应用。处理器的计算吞吐量可以用它在一段时间内执行操作的数量来衡量。因为GPU有很多SIMT指令和计算核心,所以其峰值计算吞吐量通常比其他的处理器要高。但并不是所有的指令都是平等的。如果结果不能正确收敛或没有获得预期的结果,那么程序运行速度再快也没有用。对应用程序的吞吐量和正确性进行优化时,理解不同低级原语的性能、数值精确度和线程安全性方面的优缺点是很重要的。
对于以下代码段
1double v ...
GEMM优化实战
GEMM 算子详解
本篇参考:
https://zhuanlan.zhihu.com/p/1910636263666610461
https://zhuanlan.zhihu.com/p/703256080
https://zhuanlan.zhihu.com/p/441146275
1 概念
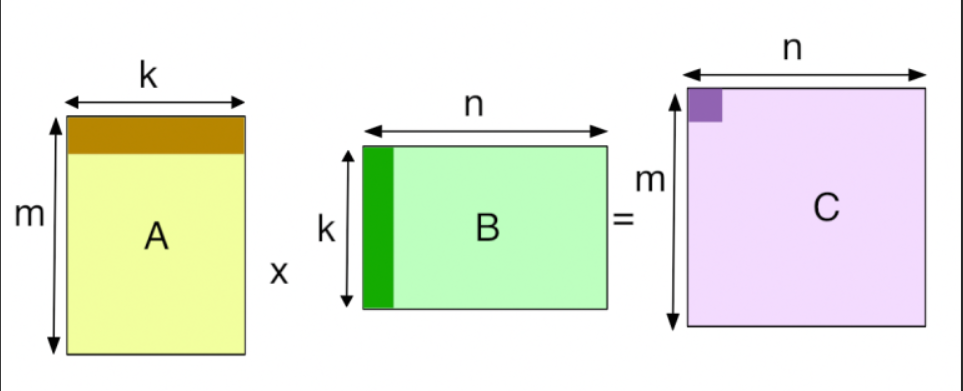
从数学上讲,GEMM 描述的是一个非常基础的线性代数运算:
C=αA×B+βCC = \alpha A \times B + \beta C
C=αA×B+βC
其中:
AAA 是 M×KM \times KM×K 的矩阵。
BBB 是 K×NK \times NK×N 的矩阵。
CCC 是 M×NM \times NM×N 的结果矩阵。
α\alphaα 和 β\betaβ 是常数标量(通常 α=1,β=0\alpha=1, \beta=0α=1,β=0)。
深度学习中 90% 以上的计算量都来自矩阵乘法:
全连接层(Linear/FC):本质就是 GEMM。
卷积层(Conv2d):通过一种叫 im2col 的技术,卷积运算会被转化为 GEMM 运行,以利用 GPU 的极致算力。
...
【CUDA】(六)流和并发
(六)流和并发
本篇笔记参考如下:
https://blog.csdn.net/DevPath/article/details/155607318
在本章前,我们的关注点可能仅限于内核级的并发,在此级别的并发中,单一的任务或内核被GPU的多个线程并行执行。本章将研究网格级的并发。在网格级并发中,多个内核在同一设备上同时执行,这往往会让设备利用率更好。
6.1 流和事件概述
CUDA流是一系列异步的CUDA操作,这些操作按照主机代码确定的顺序在设备上执行。流能封装这些操作,保持操作的顺序,允许操作在流中排队,并使它们在先前的所有操作之后执行,并且可以查询排队操作的状态。
因为所有在CUDA流中排队的操作都是异步的,所以在主机与设备系统中可以重叠执行其他操作。在同一时间内将流中排队的操作与其他有用的操作一起执行,可以隐藏执行那些操作的开销。
CUDA编程的一个典型模式是以下形式:
1.将输入数据从主机移到设备上。
2.在设备上执行一个内核。
3.将结果从设备移回主机中。
在这些情况下,可
以完全隐藏CPU和GPU之间的通信延迟。通过将内核执行和数据传输调度到不同的流中,这些操作可以重叠 ...
【CUDA】(五)共享内存和常量内存
(五)共享内存和常量内存
本篇笔记参考如下:
https://blog.csdn.net/D1557329860/article/details/143813183?ops_request_misc=&request_id=&biz_id=102&utm_term=共享内存&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-2-143813183.142
通过安排全局内存访问模式,我们学会了如何实现良好的性能并且避免了浪费事务。未对齐的内存访问是没有问题的,因为现代的GPU硬件都有一级缓存,但在跨全局内存的非合并内存访问,仍然会导致带宽利用率不会达到最佳标准。根据算法性质和相应的访问模式,非合并访问可能是无法避免的。然而,在许多情况下,使用共享内存来提高全局内存合并访问是有可能的。
5.1 CUDA共享内存概述
GPU中有两种类型的内存:
板载内存
片上内存
全局内存是较大的板载内存,具有相对较高的延迟。共享内存是较小的片上内存,具有相对较 ...
【CUDA】(四)全局内存
(四)全局内存
本篇笔记参考如下:
https://blog.csdn.net/weixin_33298352/article/details/156397919?ops_request_misc=&request_id=&biz_id=102&utm_term=统一内存&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-156397919.142
https://face2ai.com/CUDA-F-4-5-使用统一内存的向量加法/
在本章,我们将剖析核函数与全局内存的联系及其对性能的影响。通过分析不同的全局内存访问模式来实现通过核函数高效地利用全局内存。
4.1 CUDA内存模型概述
内存的访问和管理是所有编程语言的重要部分。因为多数工作负载被加载和存储数据的速度所限制,所以有大量低延迟、高带宽的内存对性能是十分有利的。
4.1.1 内存层次结构的优点
应用程序不会在某一时间点访问任意数据或运行任意代码。应用程序往往遵循局部性原则,这 ...

论文分享:Adaptive Auto-Tuning Framework for Global Exploration of Stencil Optimization on GPUs
论文分享:Adaptive-Auto-Tuning-Framework-for-Global-Exploration-of-Stencil-Optimization-on-GPUs
1 概述
GSTuner:自适应自动调优框架,可以高效地确定模板计算在GPU上的全局优化空间的最佳参数设置。
实现步骤如下:
程序生成 (Generation):首先生成满足对称邻域访问模式的随机模板程序,为后续训练提供多样化的样本。
模型训练 (Training):通过特征提取和数据预处理,统一不同优化组合(OC)的特征向量长度,训练用于预测性能的回归模型。
空间采样 (Sampling):不再盲目搜索,而是利用预测模型指导采样。根据“配额奖励政策”动态调整不同优化组合的采样比例,优先探索潜力区域 。
演化搜索 (Search):在缩小后的空间内,利用定制的遗传算法进行最终搜索。该算法以“子群相似度”作为终止条件,从而降低计算开销。
核心贡献:
全局探索能力:不同于以往仅针对特定优化组合(OC)的工具,GSTuner 分析了不同优化选择对性能的综合影响,并验证了参数设置对网格尺寸的自适应性 。
特 ...

论文分享:Moirae Generating High-Performance Composite Stencil Programs with Global Optimizations
论文分享:Moirae: Generating High-Performance Composite Stencil Programs with Global Optimizations
1 概述
模板计算:
7点模板(3D):在三维空间中,访问中心点及其上下、左右、前后的6个邻居。
27点模板(3D):访问一个 3×3×33\times3\times33×3×3 立方体内的所有点。
由于物理模型越来越复杂,现在的计算不再是跑一个简单的公式,而是由一系列相互依赖的模板操作构成的有向无环图(DAG),这就是所谓的复合模板(Composite Stencil)
Moirae框架:将图优化(如算子融合)与内核优化(如分块、流处理)结合在一起,处理由多个相互依赖的模板构成的有向无环图(DAG),认识到图优化和内核优化之间存在复杂的相互影响,因此通过搜索全局优化空间来寻找最优组合,避免陷入局部最优。该框架能够生成具有最优全局优化的复合模板高性能代码。
论文将复合模板的性能优化分为两类:图优化和核函数优化。图优化将多个模板融合到单一GPU内核中,利用模板间局部性,而内核优化则高效地将融合后的 ...